作者: 李鹏,王明,施晨,黄俊
导读
随着深度学习大语言模型的不断发展,其模型结构和量级在快速演化,依托大模型技术的应用更是层出不穷。对于广大开发者来说不仅要考虑如何在复杂多变的场景下有效的将大模型消耗的算力发挥出来,还要应对大模型的持续迭代。开发简单易用的大模型训练工具就成了应对以上问题广受关注的技术方向,让开发者专注于大模型解决方案的开发,降低大模型训练加速性能优化和训练/推理全流程搭建的人力开发成本。阿里云机器学习平台PAI开源了业内较早投入业务应用的大模型训练工具Pai-Megatron-Patch,本文将详解Pai-Megatron-Patch的设计原理和应用。
Pai-Megatron-Patch是什么
Pai-Megatron-Patch工具是阿里云机器学习平台PAI算法团队研发,基于阿里云智算服务PAI-灵骏平台的大模型最佳实践解决方案配套工具,旨在帮助大模型开发者快速上手灵骏产品,完成大语言模型(LLM)的高效分布式训练,有监督指令微调,模型离线推理验证等完整大模型开发链路。该项目提供了业界主流开源大模型基于Megatron-LM的训练&离线推理验证流程,方便用户快速上手大模型训练。
主要特性
丰富且简单易用的使用示例,支持大模型预训练,微调,评估和推理,强化学习全流程最佳实践
开源地址
https://github.com/alibaba/Pai-Megatron-Patch
技术架构
关键技术
1. 模型权重转换
下面我们以llama-2为例,详解从huggingface到megatron的模型权重转换技术。下表总结了两者在不同module上的命名对应关系。在patch实现过程中,我们首先将HF格式的ckpt转换到一种内部格式,然后再把这种内部格式转换成对应的外部格式。这样做可以最大程度复用已有的转换逻辑来处理新模型。在转换为内部格式的过程中,q_proj, k_proj, v_proj需要沿着第0维拼接在一起后赋值给内部变量query_key_value。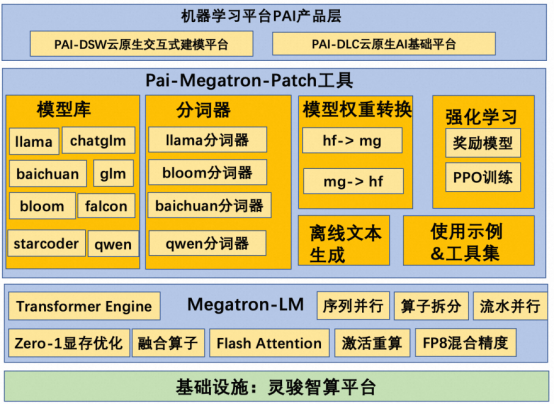
--swiglu --use-rotary-position-embeddings --no-position-embedding --untie-embeddings-and-output-weights --disable-bias-linear
--swiglu --use-alibi-mask --position-embedding-type none --untie-embeddings-and-output-weights --disable-bias-linear
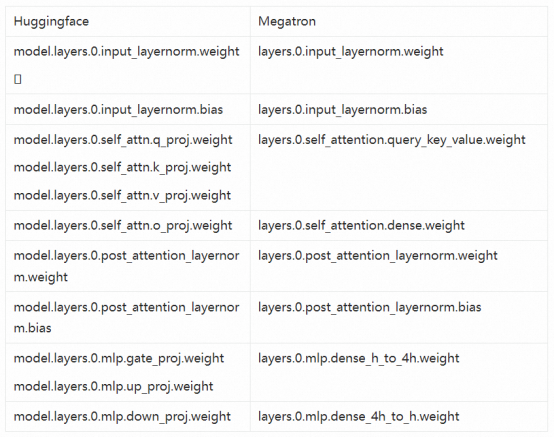
从Huggingface到TE模型的权重转换技术和之前是类似的,也需要事先找到两者之间的映射关系。从下表可以看出,TE中多了_extra_state是用来存fp8训练的scale和history的,这些在加载的时候会出现冲突,这时只要将load_state_dict函数的strict设置成False就可以了,比如load_state_dict(state_dict_, strict=False)。
for i in range(tp_size): params_dict = get_element_from_dict_by_path(output_state_dict[i], "model.language_model.encoder") dense_h_to_4h_1_name = 'mlp.dense_h_to_4h_1.weight' dense_h_to_4h_1_layer_name = f"layers.{layer}.{dense_h_to_4h_1_name}" dense_h_to_4h_1_weight = params_dict[dense_h_to_4h_1_layer_name] dense_h_to_4h_2_name = 'mlp.dense_h_to_4h_2.weight' dense_h_to_4h_2_layer_name = f"layers.{layer}.{dense_h_to_4h_2_name}" dense_h_to_4h_2_weight = params_dict[dense_h_to_4h_2_layer_name] dense_h_to_4h_name = 'mlp.dense_h_to_4h.weight' dense_h_to_4h_layer_name = f"layers.{layer}.{dense_h_to_4h_name}" params_dict[dense_h_to_4h_layer_name] = torch.cat( [dense_h_to_4h_1_weight, dense_h_to_4h_2_weight], dim=0)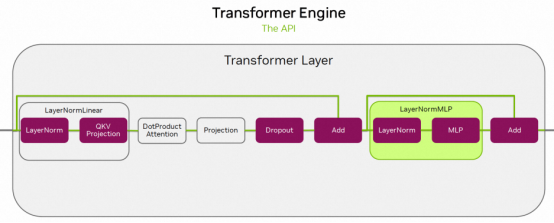

Step2: 获取需要扩充的词表
if [ $PR = fp16 ]; then pr_options=" --fp16"elif [ $PR = bf16 ]; then pr_options=" --bf16"elif [ $PR = fp8 ]; then pr_options=" --bf16 --fp8-hybrid --fp8-amax-compute-algo max --fp8-amax-history-len 1024 --transformer-impl transformer_engine"fi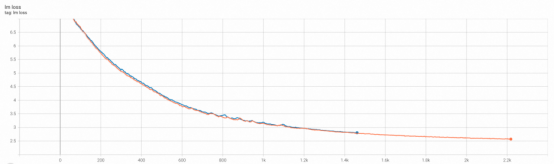
cd /mnt/workspace/mkdir llama2-ckptscd llama2-ckptswget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/
models/pai-megatron-patch/llama2-ckpts/Llama-2-7b-hf.tgztar -zxf Llama-2-7b-hf.tgzmv Llama-2-7b-hf llama2-7b-hfcd /mnt/workspace/PAI-Megatron-Patch/toolkits/model_checkpoints_convertor/llamash model_convertor.sh /root/Megatron-LM-23.04 /mnt/workspace/llama2-ckpts/llama2-7b-hf /mnt/workspace/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1 1 1 llama-7b 0 false
Step3: 词表扩充
注意设置正确的数据集挂载路径WORK_DIR以及运行环境ENV,运行示例如下所示:
3)有监督微调
ENV=$1 # 运行环境: dlc, dswMEGATRON_PATH=$2 # 设置开源Megatron的代码路径MEGATRON_PATCH_PATH=$3 # 设置Megatron Patch的代码路径MODEL_SIZE=$4 # 模型结构参数量级:7B, 13BBATCH_SIZE=$5 # 每卡训练一次迭代样本数: 4, 8GLOBAL_BATCH_SIZE=$6 # 全局batch sizeLR=$7 # 学习率: 1e-5, 5e-5MIN_LR=$8 # 最小学习率: 1e-6, 5e-6SEQ_LEN=$9 # 序列长度PAD_LEN=${10} # Padding长度:100EXTRA_VOCAB_SIZE=${11} # 词表扩充大小PR=${12} # 训练精度: fp16, bf16TP=${13} # 模型并行度PP=${14} # 流水并行度AC=${15} # 激活检查点模式: sel, fullDO=${16} # 是否使用Megatron版Zero-1降显存优化器: true, falseFL=${17} # 是否使用Flash Attention: true, falseSP=${18} # 是否使用序列并行: true, falseSAVE_INTERVAL=${19} # 保存ckpt的间隔DATASET_PATH=${20} # 训练数据集路径PRETRAIN_CHECKPOINT_PATH=${21} # 预训练模型路径TRAIN_TOKENS=${22} # 训练token数WARMUP_TOKENS=${23} # 预热token数OUTPUT_BASEPATH=${24} # 训练输出文件路径
export WORK_DIR=/mnt/workspacecd ${WORK_DIR}/PAI-Megatron-Patch/examples/llama2bash run_pretrain_megatron_llama.sh dlc /root/Megatron-LM-23.04 ${WORK_DIR}/PAI-Megatron-Patch 7B 1 16 1e-5 1e-6 2048 80 0 fp16 1 1 sel true false false 100000 ${WORK_DIR}/llama2-datasets/wudao/wudao_llamabpe_text_document ${WORK_DIR}/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1 100000000 10000 ${WORK_DIR}/output_megatron_llama2/
在微调开始之前,请先进入
https://github.com/alibaba/Pai-Megatron-Patch/blob/main/toolkits/pretrain_data_preprocessing/README.md
获取json文件。运行run_finetune_megatron_llama.sh脚本,需要传入的参数列表如下:
ENV=$1 # 运行环境: dlc, dswMEGATRON_PATH=$2 # 设置开源Megatron的代码路径MEGATRON_PATCH_PATH=$3 # 设置Megatron Patch的代码路径MODEL_SIZE=$4 # 模型结构参数量级: 7B, 13BBATCH_SIZE=$5 # 每卡训练一次迭代样本数: 4, 8LR=$6 # 学习率: 1e-5, 5e-5MIN_LR=$7 # 最小学习率: 1e-6, 5e-6SEQ_LEN=$8 # 序列长度PAD_LEN=$9 # Padding长度:100EXTRA_VOCAB_SIZE=${10} # 词表扩充大小PR=${11} # 训练精度: fp16, bf16TP=${12} # 模型并行度PP=${13} # 流水并行度AC=${14} # 激活检查点模式: sel, fullDO=${15} # 是否使用Megatron版Zero-1降显存优化器: true, falseFL=${16} # 是否使用Flash Attention: true, falseSP=${17} # 是否使用序列并行: true, falseTRAIN_DATASET_PATH=${18} # 训练数据集路径VALID_DATASET_PATH=${19} # 验证数据集路径PRETRAIN_CHECKPOINT_PATH=${20} # 预训练模型路径EPOCH=${21} # 训练迭代轮次OUTPUT_BASEPATH=${22} # 训练输出文件路径
export WORK_DIR=/mnt/workspacecd ${WORK_DIR}/PAI-Megatron-Patch/examples/llama2sh run_finetune_megatron_llama.sh dlc /root/Megatron-LM-23.04 ${WORK_DIR}/PAI-Megatron-Patch 7B 1 1e-5 1e-6 2048 80 0 fp16 1 1 sel true false false ${WORK_DIR}/llama2-datasets/wudao_train.json ${WORK_DIR}/llama2-datasets/wudao_valid.json ${WORK_DIR}/llama2-ckpts/llama2-7b-hf-to-megatron-tp1-pp1 2 ${WORK_DIR}/output_megatron_llama2/
ENV=$1 # 运行环境: dlc, dswMEGATRON_PATH=$2 # 设置开源Megatron的代码路径MEGATRON_PATCH_PATH=$3 # 设置Megatron Patch的代码路径CHECKPOINT_PATH=$4 # 模型微调阶段的模型保存路径MODEL_SIZE=$5 # 模型结构参数量级: 1.1B, 1.7B, 7.1BTP=$6 # 模型并行度BS=$7 # 每卡推理一次迭代样本数: 1, 4, 8SEQ_LEN=$8 # 序列长度: 256, 512, 1024PAD_LEN=$9 # PAD长度:需要将文本拼接到的长度EXTRA_VOCAB_SIZE=${10} # 模型转换时增加的token数量PR=${11} # 推理采用的精度: fp16, bf16TOP_K=${12} # 采样策略中选择排在前面的候选词数量(0-n): 0, 5, 10, 20INPUT_SEQ_LEN=${13} # 输入序列长度: 512OUTPUT_SEQ_LEN=${14} # 输出序列长度: 256INPUT_FILE=${15} # 需要推理的文本文件: input.txt, 每行为一个样本OUTPUT_FILE=${16} # 推理输出的文件: output.txt# TOP_K和TOP_P必须有一个为0TOP_P=${17} # 采样策略中选择排在前面的候选词百分比(0-1): 0, 0.85, 0.95TEMPERATURE=${18} # 采样策略中温度惩罚: 1-nREPETITION_PENALTY=${19} # 避免生成是产生大量重复,可以设置为(1-2)默认为1.2
此处提供一个离线推理输出的文件,推理的数据组织形式需要与微调时的保持一致。
https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/
pai-megatron-patch/llama2-datasets/pred_input.jsonl
以下有监督微调过程保存模型的推理代码,需要将run_text_generation_megatron_llama.sh脚本中CUDA_VISIBLE_DEVICES参数设置为0;GPUS_PER_NODE参数设置为1;同时使用下列代码进行推理。此时使用单卡进行推理。注意:此处模型tp为1,可使用单卡推理;如果tp>1,则需使用相应卡数进行推理。
一般来说,SFT微调过的模型在对话场景已经会有不错的表现了。如果想进一步提升模型效果,可以再加上RLHF训练。包括奖励模型(Reward Model)的训练和强化学习(PPO)的训练。这里展示了如何使用当前最常用的RLHF开源代码框架,DeepSpeed-Chat和trlx,来进行奖励函数训练(RM),以及强化学习优化(PPO)。
export WORK_DIR=/mnt/workspacecd ${WORK_DIR}/PAI-Megatron-Patch/examples/llama2bash run_text_generation_megatron_llama.sh dsw /root/Megatron-LM-23.04 ${WORK_DIR}/PAI-Megatron-Patch ../../../llama2-train 7B 1 1 1024 1024 0 fp16 10 512 512 ${WORK_DIR}/pred_input.jsonl ${WORK_DIR}/llama2_pred.txt 0 1.0 1.2
cd PAI-Megatron-Patch/toolkits/model_checkpoints_convertor/gpt3_llamabash model_convertor.sh /path/to/Megatron-LM /path/to/megatron_llama2_ckpt /path/to/hf_llama2_ckpt 1 1 llama-7b 0 true
cd PAI-Megatron-Patch/toolkits/model_checkpoints_convertor/bloombash model_convertor_huggingface_megatron.sh /path/to/Megatron-LM /path/to/megatron_bloom_ckpt /path/to/hf_bloom_ckpt 1 1 true
下载安装开源社区DeepSpeed-Chat源代码:
基于GPT-J模型训练奖励模型(RM):
开源生态——构想和未来
在PAI-Megatron-Patch的开发过程中,我们围绕中文大模型训练加速落地沉淀了以下几个方面的内容:
cd PAI-Megatron-Patch/rlhf/deepspeed-chatgit clone https://github.com/microsoft/DeepSpeedExamples.gitcp -f rm_main.py DeepSpeedExamples/applications/DeepSpeed-Chat/training/
step2_reward_model_finetuning/main.pycp -f utils.py DeepSpeedExamples/applications/DeepSpeed-Chat/training/
utils/utils.pycd DeepSpeedExamples/applications/DeepSpeed-Chat/pip install -r requirements.txt
cd training/step2_reward_model_finetuning/ && bash training_scripts/
llama2/run_llama2_7b.sh
cd training/step3_rlhf_finetuning/ && bash training_scripts/llama2/run_llama2_7b_lora.sh
cd PAI-Megatron-Patch/rlhf/trlxgit clone https://github.com/CarperAI/trlx.gitcp trlx_bloom_rlhf.py trlx_bloom_rlhf_test.py trlx/examples/summarize_rlhf/cp train_reward_model_bloom.py reward_model_bloom.py ds_config_bloom.json trlx/
examples/summarize_rlhf/reward_model/cp -f ds_config_trlx_gptj_summarize.json trlx/examples/summarize_rlhf/configs/cd trlxpip install -e .
cd examples/summarize_rlhf/reward_model/ && deepspeed train_reward_model_bloom.py
cd examples/summarize_rlhf/reward_model/ && deepspeed train_reward_model_gptj.py
cd examples/summarize_rlhf/ && accelerate launch --config_file configs/
default_accelerate_config.yaml trlx_bloom_rlhf.py
cd examples/summarize_rlhf/ && accelerate launch --config_file configs/
default_accelerate_config.yaml trlx_gptj_text_summarization.py
cd examples/summarize_rlhf/ && accelerate launch --config_file configs/
default_accelerate_config.yaml trlx_bloom_rlhf_test.py
Huggingface的模型权重无损转换成Megatron或者Transformer Engine可读的模型权重。
H800集群开启FP8混合精度训练确保收敛。
LLM大模型在PAI灵骏智算平台上的最佳实践。
强化学习技术在PAI灵骏智算平台上的最佳实践。
[1]. Attention Is All You Need
[7]. Llama 2: Open Foundation and Fine-Tuned Chat Models
[8]. Benchmarking Large Language Models on NVIDIA H100 GPUs with CoreWeave








CopyRight@2015-2026 中国品牌要闻网 All Right Reserved
工信备案号:沪ICP备 2023001279号


